



思路如下 注:最后仅爬取了部分视频,并未完整爬完
1. 获取所有的视频名和地址
翻页时发现,有如下请求。则可以通过修改后面的数字来获取请求
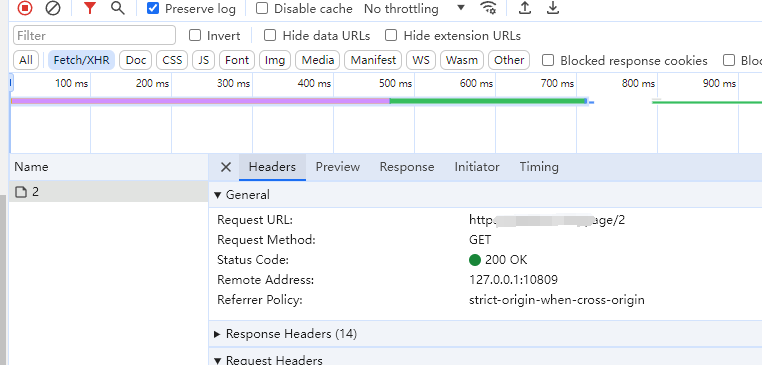
然后查看返回数据,从返回的数据中获取视频的名称和详情页地址
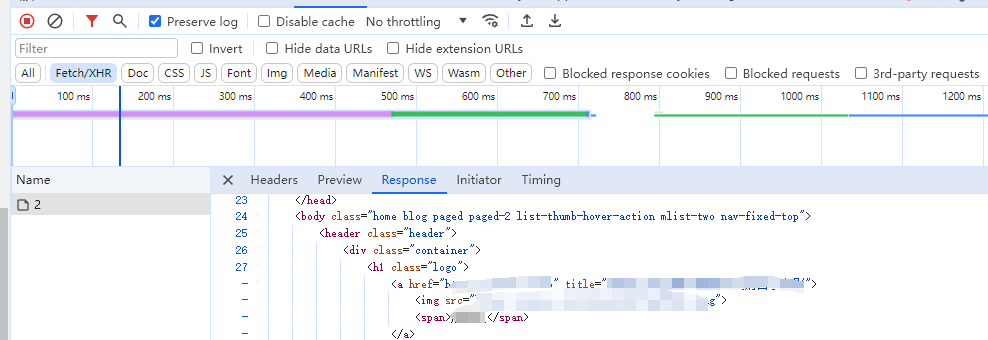
发现返回的是html,数据。然后编写正则表达式来获取数据。title和link地址
具体方法见parse_page_content
然后将数据保存到csv文件中,用来后续获取视频地址,
保存csv见save_to_csv

然后我们会获得一个csv文件,里面有两行数据,一行title和一行地址
2. 获取视频地址
通过上面的代码我们获取了详情页的地址,我们在循环访问地址来获取视频地址
我们先手动访问地址

发现视频是通过iframe嵌入到详情页里面的,而且iframe框的地址每次都会变化,于是通过get_video_url来获取iframe的地址
然后再次访问具体的视频播放地址。访问时通过postman发现会报错404 ,于是加入Referer参数再次访问,成功,应该是比较常用的Referer防盗链。后面的请求都加上Referer基本上都ok
然后通过播放,发现m3u8地址。查看了源代码,如下,获取m3u8地址
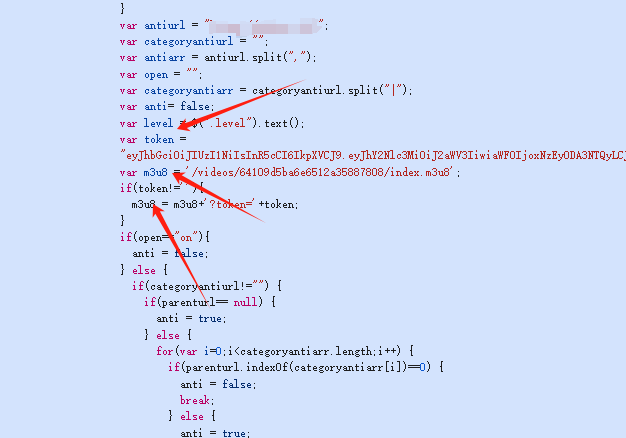
最后有了方法extract_info_from_url来获取最后的m3u8地址
3. 下载
上面我们获取了m3u8地址之后我们需要下载视频文件。具体方法见download_m3u8
共三步
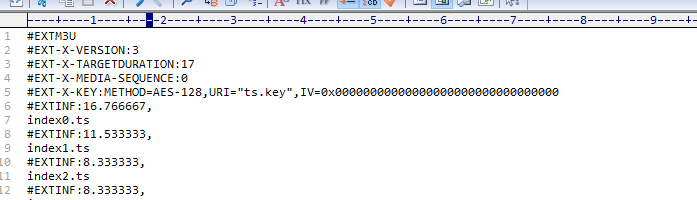
1.下载m3u8文件,用来播放和做引导 可以在保存m3u8是将ts.key的地址修改为本地。
2.下载ts.key来解密
3.下载所有的ts视频文件。这个是具体的ts文件
下面给到m3u8文件示例
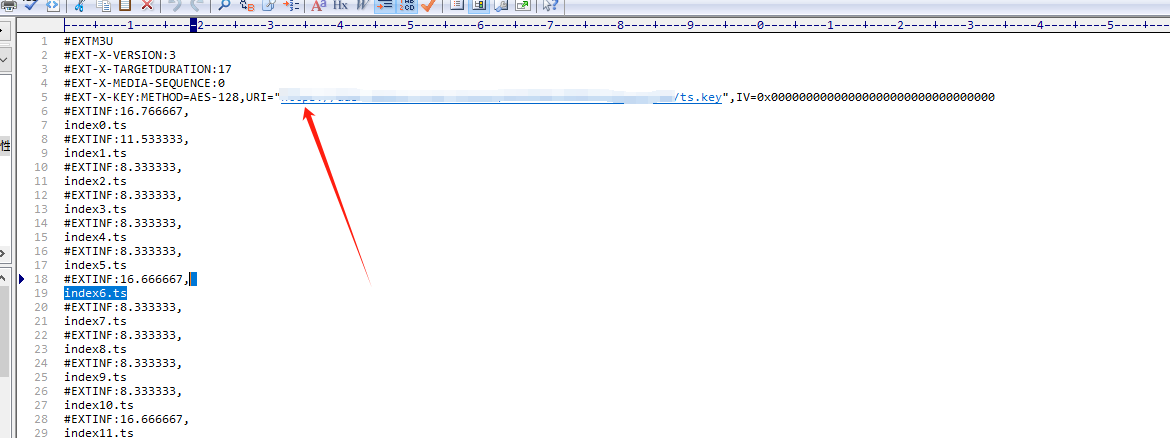
最后内容如下即可播放

4. 源代码
import requests
from bs4 import BeautifulSoup
import csv
import time
import re
import os
def get_page_content(url):
response = requests.get(url)
if response.status_code == 200:
return response.text
else:
return None
def parse_page_content(content):
soup = BeautifulSoup(content, 'html.parser')
articles = soup.find_all('article', class_='excerpt')
data = []
for article in articles:
title = article.find('h2').text.strip()
link = article.find('a', class_='thumbnail').get('href')
data.append({'title': title, 'link': link})
return data
def save_to_csv(data, filename):
with open(filename, 'a', newline='', encoding='utf-8-sig') as csvfile:
fieldnames = ['title', 'link']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
for item in data:
writer.writerow({'title': item['title'], 'link': item['link']})
def main():
base_url = 'https://xxxx.xxx/page/'
page = 1
seen_titles = set() # 存储已经见过的标题
filename = 'videos.csv'
while True:
url = base_url + str(page)
content = get_page_content(url)
if content:
data = parse_page_content(content)
if not data or any(item['title'] in seen_titles for item in data):
print('No more data or found duplicate data. Exiting loop.')
break
seen_titles.update(item['title'] for item in data)
save_to_csv(data, filename)
print(f'Data from page {page} saved successfully.')
page += 1
time.sleep(10) # 每次请求后等待 10 秒
else:
print(f'Failed to fetch page {page} content. Exiting loop.')
break
def get_video_url(url):
try:
# 发送GET请求获取网页内容
response = requests.get(url)
# 使用BeautifulSoup解析HTML
soup = BeautifulSoup(response.content, 'html.parser')
# 找到所有<article>标签
articles = soup.find_all('article', class_='article-content')
for article in articles:
# 找到所有<iframe>标签
iframes = article.find_all('iframe')
for iframe in iframes:
# 获取iframe中的src属性值
src = iframe.get('src')
# 如果src属性值包含指定的关键字,则返回该地址
if 'xxxx.xxxx/share/' in src:
return src
# 如果没有找到符合条件的地址,则返回None
return None
except Exception as e:
print("An error occurred:", e)
return None
def extract_info_from_url(url):
try:
# 发送GET请求获取页面内容
response = requests.get(url)
source_code = response.text
#print(source_code)
# 调试输出源代码
antiurl_match = re.search(r'var\s+antiurl\s*=\s*"(.*?)";', source_code)
token_match = re.search( r'var\s+token\s*=\s*"([^"]+)"', source_code)
m3u8_match = re.search(r'var\s+m3u8\s*=\s*\'([^"]+\.m3u8)\'', source_code)
if antiurl_match and token_match and m3u8_match:
antiurl = "https://xxx.xxx.xxx" #antiurl_match.group(1)
token = token_match.group(1)
m3u8 = m3u8_match.group(1)
# 拼接最终的播放地址
final_url = f"{antiurl}{m3u8}?token={token}"
return final_url
else:
print("无法找到匹配的信息。")
return None
except Exception as e:
print("An error occurred:", e)
return None
def download_m3u8(url, referer, filename):
headers = {
'Referer': referer,
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36',
'Accept':'*/*',
'Accept-Encoding':'gzip, deflate, br, zstd',
'Connection':'keep-alive'
}
response = requests.get(url, headers=headers)
m3u8_content = response.text
# 解析m3u8文件,提取ts文件链接
ts_urls = [line.strip() for line in m3u8_content.split('\n') if line.endswith('.ts')]
# 创建保存ts文件的目录
if not os.path.exists(filename):
os.makedirs(filename)
m3u8Name = os.path.join(filename, "index.m3u8")
with open(m3u8Name, 'wb') as f:
f.write(response.content)
match = re.search(r'(https?://\S+?)/index\.m3u8', url)
extracted_url = match.group(1)
key_url = extracted_url + "/ts.key"
key_response = requests.get(key_url, headers=headers)
keyName = os.path.join(filename, "ts.key")
with open(keyName, 'wb') as f:
f.write(key_response.content)
# 下载ts文件
for i, ts_url in enumerate(ts_urls):
ts_url= extracted_url+"/"+ts_url
ts_filename = f'index{i}.ts'
ts_filepath = os.path.join(filename, ts_filename)
with open(ts_filepath, 'wb') as f:
print(f'Downloading {ts_url}...')
response = requests.get(ts_url, headers=headers)
f.write(response.content)
print('Download completed.')
def get_video(url,filename):
video_url = get_video_url(url)
if video_url:
print("视频地址:", video_url)
final_url = extract_info_from_url(video_url)
print("最终视频视频地址:", final_url)
download_m3u8(final_url,video_url,"mp4/"+filename.replace('/', '_'))
else:
print("未找到视频地址。")
def download_csv():
filename = 'videos.csv'
with open(filename, 'r', newline='', encoding='utf-8-sig') as csvfile:
reader = csv.DictReader(csvfile)
for row in reader:
title = row['title']
link = row['link']
print(f'Processing video: {title}')
# 在这里调用你需要的函数,比如下载视频或其他操作
# 下面是一个示例,你需要根据实际情况进行调整
get_video(link, title)
time.sleep(2) # 可以添加适当的延迟,避免过于频繁的操作
if __name__ == '__main__':
download_csv()


评论区